Transferring data between pipelines¶
It's often advisable to break up a very complex pipeline into several pipelines which pass data to each other. This not only makes it easier to maintain, but may allow you to reuse certain pipelines for multiple purposes. This also allows you to distribute processing between multiple computers.
One example would be a pipeline that performs preprocessing (which we'll call pipelineA, and then two other pipelines which perform different spectral analyses from that same preprocessed data (pipelineB and pipelineC). This could easily be a single pipeline but potentially a good candidate for 3 separate pipelines.
See the page on running multiple pipelines simultaneously for information on how to do that.
Streaming data¶
When working with streaming data, add one or more LSLOutput nodes to pipelineA and give them unique stream names. Be sure to also provide a stream_id which can simply be the stream name plus some random characters. This is needed for LSLInput nodes to automatically reconnect if the stream drops off (though that's unlikely to happen when both the LSLOutput and LSLInput are on the same computer).
In this example, we'll take a standard preprocessing chain and add an LSLOutput node with stream name preprocessed. Note the source_id property.
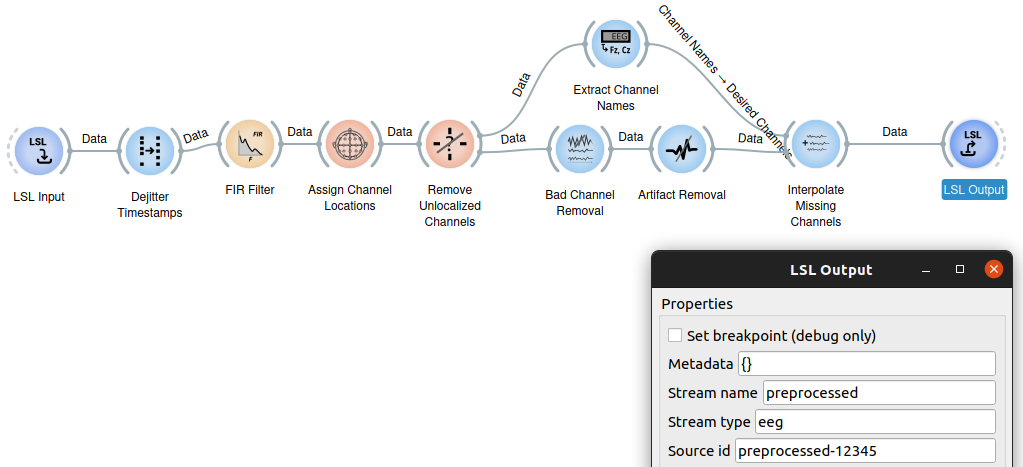
Then in pipelineB and pipelineC, start with an LSLInput node that captures the stream created with pipelineA.
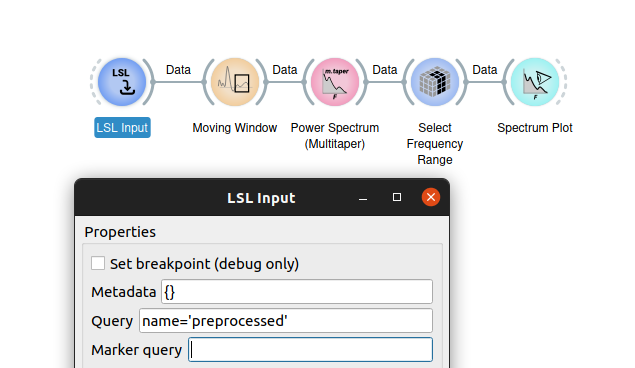
Each of these pipelines can create several outputs and have several inputs. However, bear in mind that LSL expects a time series consisting of a two-dimensional matrix. Usually this is space (channels) x time, but can be any two axes. If the data that you wish to pass from one pipeline to another has more than two dimensions, you'll need to reduce it to 2 dimensions. (You can use Mean to average over a particular axis and then StripSingletonAxis to remove it.)
Offline data¶
For offline data, one pipeline can save the data to a file which is then read in by the second pipeline. In this case the two pipelines can be run sequentially rather than simultaneously. To accomplish this in a lossless manner, that is, fully preserving all axis data and stream properties, use the RecordToREC node to save the data to disk, and the PlaybackREC to import it. Alternatively, you can use the ExportStructure to save the data to disk in one pipeline, and ImportStructure in the second pipeline to load it back. (Note that RecordToREC will work with offline data or on streaming data which will append each packet to the file as it is received by the node, and PlaybackREC will restream those same packets sequentially. Whereas ExportStructure and ImportStructure will only work with offline data.)